Pricing Models
How InsurAce calculates cover product pricing.
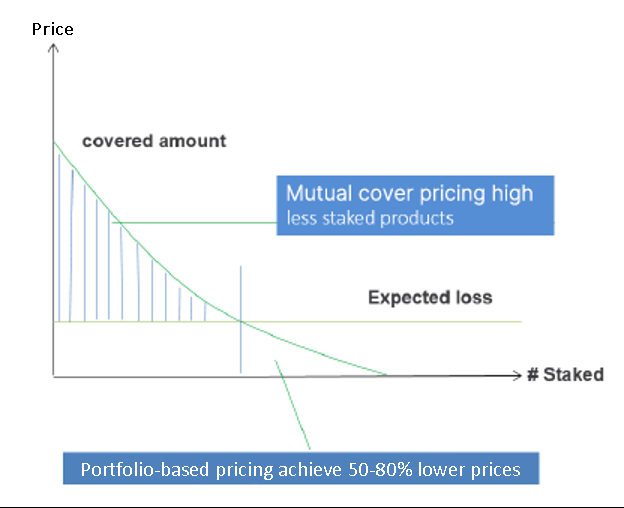
Most pricing models by blockchain-based cover providers rely heavily on the value staked in their protocols, i.e. the higher the value staked, the lower their cover products can be priced. This staking-driven price structure fails to properly assess a protocol's actual risks, likely causing cover providers to significantly over-charge users for covers when less funds are staked in their protocol.
Base Price
InsurAce.io adopts actuarial pricing models to substantially mitigate the above issue by assessing the expected loss of cover products fairly. At the same time, InsurAce.io will be able to reduce costs and enhance its ability to provide cover.
When conducting loss assessments, InsurAce.io consolidates price and risk scores for all protocols at the portfolio-level.
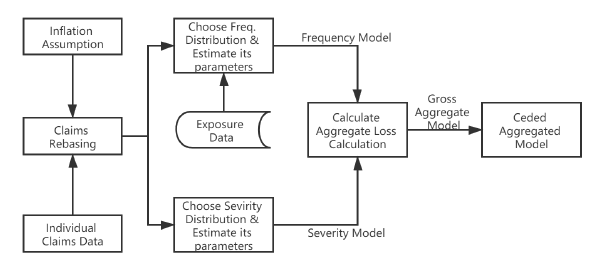
InsurAce.io follows the Aggregate Loss Distribution model's key actuarial concepts to estimate expected loss at the portfolio level. The model's workflow is illustrated below.
The model's main inputs are the number/amount of claims and number/amount of exposures in a given time period, which will be used for selecting and training two separate models - the frequency model and the severity model. Frequency modeling produces a model that calibrates the probability of a given number of losses occurring during a specific period, while severity modeling produces the distribution of loss amounts and sets the level of deductibles and the limits of cover amounts. When both models have been well estimated, they are combined to determine aggregate loss.
InsurAce.io then incorporates aggregate loss into protocol risk factors and formulates calculations to get the base price for each protocol.
The models' parameters are initially defined, devised, and validated using historical data. After that there will be continuous refinement and optimization of said parameters based on new data that is constantly being collected and machine-learning methods adopted by InsurAce.io.
Dynamic Pricing
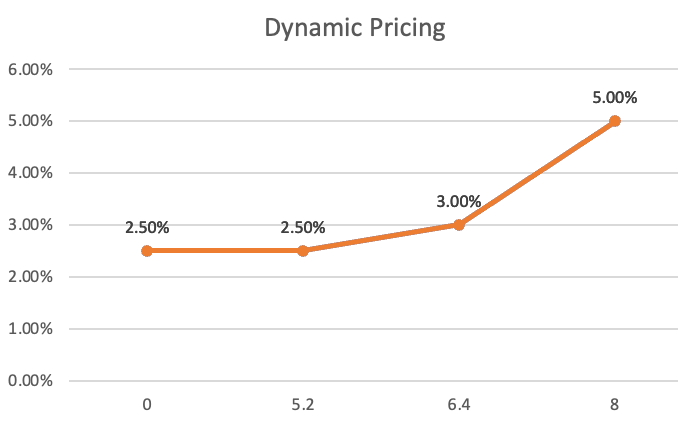
The actual pricing for each cover product will be determined by the cover product's supply and demand, starting from a minimum or base price up to a maximum price of three times the base price. In other words, the more covers sold, the higher the price and vice-versa.
For each product, the price for the first 65% of total capacity will remain unchanged. The price for the remaining capacity will increase following a dynamic pricing model.
Example: Base annual price of 2.5% with a total capacity of 8M.
The price for the first 65% of of the 8M capacity sold (5.2M) remains unchanged at 2.5%.
The price for the remaining 35% of capacity will gradually increase up to a maximum of two times the base price (i.e. 5.0%) when 100% of capacity is sold.
The figures used in the above example are just for illustration purposes. Actual settings for each cover product are subject to change.
Last updated